大資料的環境需求
步上雲端的時代,運算與儲存空間隨著莫爾定律的實踐慢慢變得越來越便宜,而大資料的議題也越來越被重視,在Google這麼一個以大資料起家的企業,從一開始的分散式儲存體GFS(Google File System)到大資料分析工具MapReduce的概念,讓我們知道在大資料處理上,儲存(Input)與讀取(Output)兩個不可或缺的環節。
分散式儲存
在傳統的架構上,存在一顆硬碟或資料庫的資料,要讓多台主機同時存取並分析資料會有許多衝突問題需要解決。而且,在雲端的概念中,要訴求一台超級電腦似乎永遠是成本遠高於利潤的作法,在雲端分毫必爭的資源環境,Google是以小而多的方式來取勝。而GFS正式以此方式讓儲存可以無限延伸,不只空間的部分得以延伸,連存取該空間所需要用到的運算能力,也可以在這個架構上得到滿足。
有效率的查詢方式
MapReduce是一種沒有index的查詢方式,從頭開始看資料,再透過所給訂的條件作過濾... 原本看似毫無效能的運作,在GFS之後漸漸變成可能... 由於GFS提供了平行的存取架構,讓原本查詢需要在一台機器上運作的傳統被打破。而基於GFS的可過展儲存方式,同一份資料可以由眾多的主機同時讀取,因此Google實作了MapReduce的架構,可以同時間讓多個運算資源存取同一份資料,因此只要使用正比於資料的大小的機器來運算,就可以把處理的時間壓縮到可以忍受的範圍。
更多的資源調用方法
當最困難的問題都已經解決,接下來的問題就相對單純了許多,而且,在現階段不論是網路環境、運算資源、儲存資源等等都持續不斷提升之下,資源的價格也在不斷的降低,這意味著適合大資料的環境已經具備... 接下來,開發者們可以集中在思考資料有意義的地方。但在資源無虞的情況下,使用資源的方式則需要再好好思考,如何自動化、如何因應量大的儲存、處理...
- 部署管理:如何在最短的時間內部署您的服務,讓他可以承受最大的request、儲存最多的資料,並且具備HA的架構...
- 自動化拓展(Auto Scale):延伸部署管理的另一個應用層面,如何在不影響服務的層面下,自動化擴展您的伺服器群,並且可以在離峰時間將資源釋放。
- 全球網路:雲端時代在步入全球存取的狀況下,我們在思考如何讓全世界的使用者可以存取無礙,已經成為雲端的課題之一。
剩下的,就是轉換傳統的思維,讓我們開始思考哪些是現存的資料,哪些是預計可以再收入的資料,結合這些資料可以得到哪些幫助。最重要的是,儲存、分析的成本,是否可以在未來進一步的轉換成為獲益!
什麼是Lambda Architecture
資料量大,意味著讀取分析的Cost變得更高,在傳統的技術稱作Data Warehouse(DW),資料在資料中心以許多大型儲存裝備儲存著,而在分析前,需要先行依照使用到的資料來建立Cube,來減少資料量,以方便後續進行分析使用。延伸這樣的概念,我們可以想像在搜集大量資料時,可以將資料的輸入分別存入批次區、即時區儲存體。在需要長時間統計時候,可以參考批次區的資料,他的運作會花較多時間,Cost比較高;而因應短期分析需要,我們可以從即時區參考,他的資料量比較少,查詢比較快,Cost相對比較低... 如此,可以讓分析的動作得到完整與即時兩個項面,這就是Lambda Architecture的精髓。

Google Cloud Platform上有哪些相關工具
對應到正在蓬勃發展中的Cloud,Google Cloud Platform(GCP)以自己的經驗轉化成服務,提供了相對應的技術讓您可以收容這些巨大資料,並且在幾近無限的運算資源輔助之下,您可以在GCP上使用最經濟實惠的方式完成大資料分析!
Google Cloud Storage
在儲存面,基於GFS的概念,Google Cloud Storage(GCS)的建構以分散為概念,透過Replica的方式將資料複製到一個以上的實體儲存裝置上,並將存取服務的方式包裝成API介面,供其他系統做介接存取。Cloud Storage在大資料服務上,佔有一個非常重要的地位,他提供以物件為單位的存放方式、物件的儲存沒有上線、支援多種存取的方式(包括:API, SDK, Fuse等等),並且在大量讀取時,存取的Endpoint具備快取及自動擴展的特性。
Cloud Pub/Sub
Cloud Pub/Sub可以想像成是雲端的儲存佇列(Queue),具備發佈跟訂閱的特性,讓開發者可以不用思考收資料的端點(Endpoint)的擴展,並且可以結合Google Cloud內部的許多應用來訂閱消化進入到該佇列的資料,並進行進一步的資料處理。
BigQuery
BigQuery是Google以MapReduce概念所實作的大資料儲存與查詢服務,在概念上,BigQuery以Column Base的方式來儲存所有的資料,提供SQL like的查詢介面,並且以大量的主機同時Full Table Scan的方法快速的過濾完所給定的條件,再做資料的整合,以資料集的方式回覆給查詢端。在BigQuery中,具備前端的資料載入端點(Streaming Insert, Cloud Storage Insert)、無限的儲存空間以及快速的反應速度。開發者可以使用最簡單的方式I/O BigQuery的服務!
Cloud Logging
Cloud Logging是Google儲存大量記錄檔案的服務,接收實作Fluentd的Client端所傳回的資料,讓所有以Fluentd做ETL資料轉換的服務可以無縫接軌到Google的雲端環境,Cloud Logging的儲存僅是一個方便資料查詢的暫存區,提供一些簡單的過濾方式讓資料可以被查詢... 性質上,他可以作為Lambda Architecture中的即時資料呈現層,讓您可以檢索近一個月所載入的記錄資訊。
Cloud Monitor
Cloud Monitor是Google所提供的Cloud Monitor API與Stackdriver所提供的Monitor Console所整合提供的一個監控服務,除了監控的數值、圖表之外,也包含了客製化告警通知功能。另外,Cloud Monitor也支援透過RESTful API來抓取監控的資料來進一步處理,以及可以把自訂的資料輸入到Custom Metrics中,達到進階監控的目的。
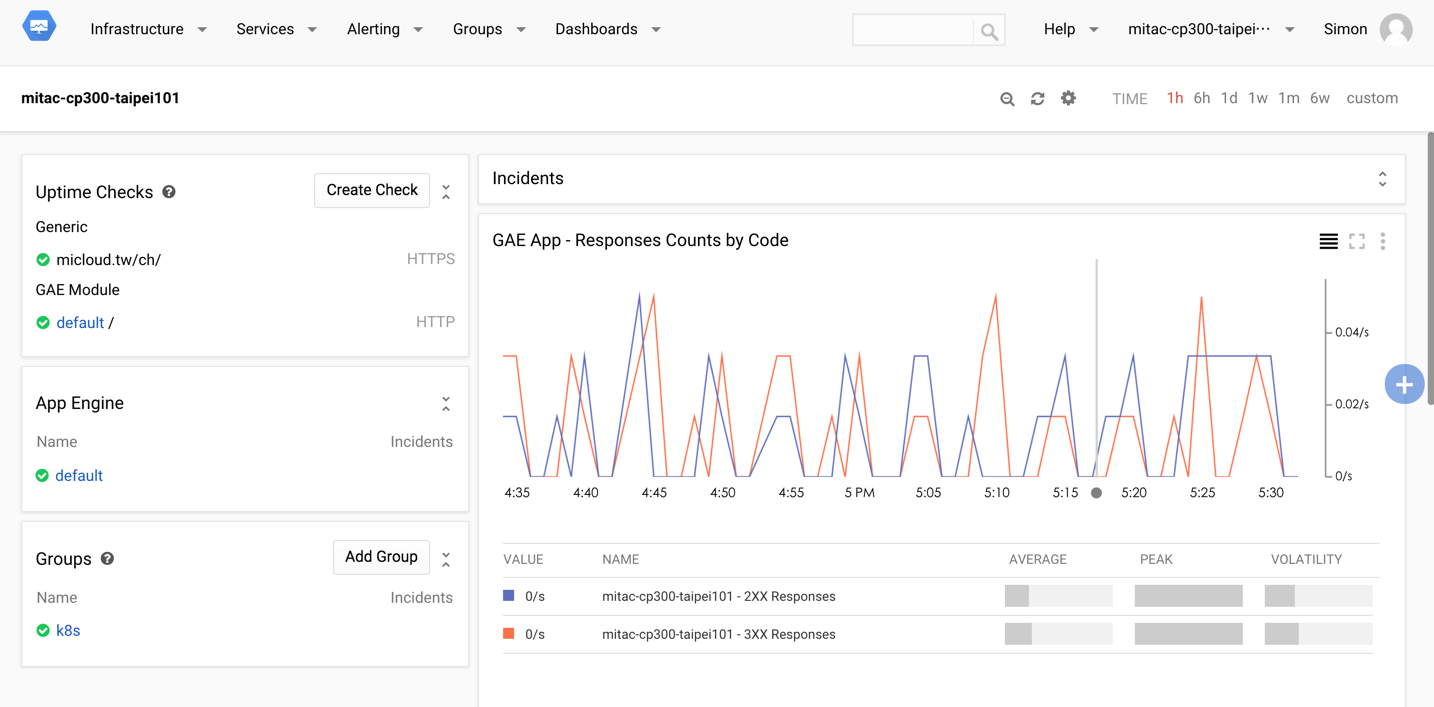
Dataflow
Dataflow是Google新推出的大資料處理方案,是一套承襲MapReduce概念的系統,以Java程式來建構整個大資料處理流程。在Dataflow,資料來源可以承接Cloud Pub/Sub、Cloud Storage以及BigQuery的資料,並且在處理完成後,回寫回Cloud Storage與BigQuery,再搭配其他的大資料處理工具進行進一步的分析作業。而整體的運作過程,由Google幫您解決處理程式的Scale out問題,以及分散運算後的資料整合問題。
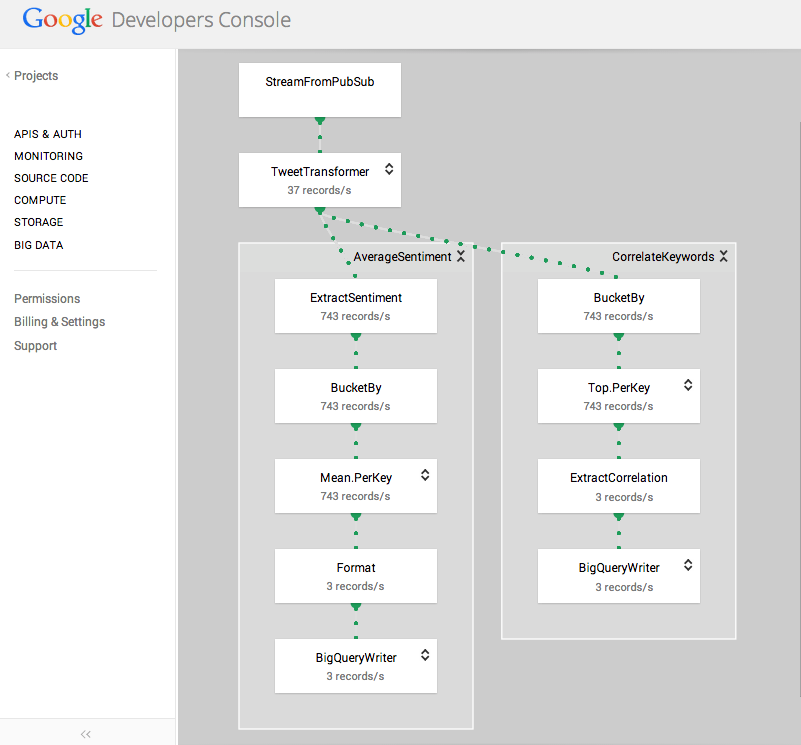
一步一步建立Google上的Lambda Architecture
在了解Google上的服務之後,稍微整理一下我們可以間單應用Google的服務在這些大資料的需求中...下面是一個簡單的資料蒐集平台,該平台希望做到大量的資料蒐集,並可以在最少的系統維運的狀態下運作,因此我們希望:
- 平台的資料進入點可以簡單設定即可蒐集資料
- 末端儲存裝置可以收容無限的資料,並提供簡單的分析方式
- 呈現端可以以服務方式呈現,以設定的方式提供給使用者
依據上面的需求,我們透過最通用的資料傳輸工具 - Fluentd來進行末端的資料蒐集作業,搭配Cloud Logging為核心作為資料蒐集的中介層,然後設定將資料載入到BigQuery服務中,最後透過Cloud Monitor服務作為Dashboard平台來達到圖表呈現與告警的目的。對照Lambda Architecture,我們可以分類如下:
- Speed Layer:
- 使用Cloud Logging的即時呈現功能,可以顯示近30天的資料,即時呈現於Cloud Logging中。
- 在fluentd client端以延伸fluentd功能設定之方式,讓資料可以同時間複製一份給即時呈現層,呈現即時報表。
- Batch Layer
- 以BigQuery為大資料儲存的最後儲存目的地,並可以透過Table Decorator[1]做小範圍的資料集合或透過Daily Table[2]等方式作為區間資料集,也可以依您的定義蒐集各種不同的記錄檔資料、交易資料等等。
- Serving Layer
- 實作排呈服務,以查詢BigQuery的各項資料集,並定期將查詢結果匯入呈現層,供呈現批次報表。在此,呈現層與Serving Layer我們可以使用Google的免費工具”Apps Script”來實作。
實作
在上面架構中,需要實作的部分包含:
- Fluentd client的設定檔,讓資料可以存入Cloud Logging,並且同時複製資料儲存到呈現層,供即時圖表繪製。
- Query engine,實作排程查詢BigQuery的方式,並將可以將資料做即時圖表呈現。
安裝google-fluentd
Google fluentd的安裝展示在他的說明文件中: https://cloud.google.com/logging/docs/agent/installation,我們可以透過該說明完成google-fluentd的安裝。
Step 1: 下載 google-fluentd 安裝腳本
curl -sSO https://storage.googleapis.com/signals-agents/logging/google-fluentd-install.sh
|
Step 2: 執行安裝腳本
sudo bash google-fluentd-install.sh
|
設定credential
如果您的fluentd client主機是位於GCE內,則上面說明安裝完成,已經可以存取Cloud Logging的服務,您只需要在/etc/google-fluentd中修改您的Input設定檔即可。如您是在GCE以外的主機安裝google-fluentd,則可以透過下面方式啟用google-fluentd
Step 1: 在您的Cloud Console建立service account 並下載 json credential 檔案
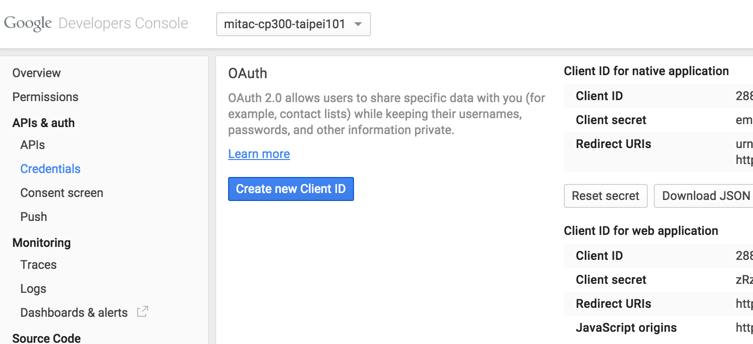
Step 2: 設定json檔案到client路徑中
複製所下載的json檔案到:“/root/.config/gcloud/application_default_credentials.json”,則google-fluentd可以使用此credential執行資料傳輸動作。
Step 3: 修改google-fluentd設定檔
最後只需要將下面設定檔案更新到/etc/google-fluentd/google-fluentd.conf,並將project_id換成您的Google Cloud Platform專案即可。
@include config.d/*.conf
<match fluent.**>
type null
</match>
<match **>
type copy
<store>
type stdout
</store>
<store>
type google_cloud
buffer_chunk_limit 512K
flush_interval 5s
max_retry_wait 300
disable_retry_limit
project_id mitac-cp300-taipei101
zone micloud
vm_id dns-master
</store>
</match>
|
Step 4: 重新啟動google-fluentd agent
$ sudo /etc/init.d/google-fluentd restart
|
實作Query Engine
在Query Engine中,我們可以按照Google所發布的Open Source專案:https://github.com/GoogleCloudPlatform/lambda-dashboard 來建置我們的Dashboard。
Step1: 複製Lambda Dashboard
Apps Script建置的部分,需要兩個Script檔案,我們可以直接從 Lambda Dashboard Demo Video 中複製這個Google Sheet,同時就會複製該Apps Script腳本,裡面的兩個Script分別是fluent_listener.gs,負責開啟HTTPS port來聆聽由fluentd client所傳來的request;bq_query.gs,提供排程查詢BigQuery的方式,並將查詢結果寫入SpreadSheet中,順便繪製圖表。

Step 2: 設定fluentd client
而在fluentd client的設定檔案中,我們需要加入https_json的一段設定到match tag中,
<match **>
type copy
<store>
type stdout
</store>
<store>
type google_cloud
buffer_chunk_limit 512K
flush_interval 5s
max_retry_wait 300
disable_retry_limit
project_id mitac-cp300-taipei101
zone micloud
vm_id dns-master
</store>
<store>
type https_json
use_https true
buffer_path /tmp/buffer
buffer_chunk_limit 256m
buffer_queue_limit 128
flush_interval 3s
endpoint <<ENDPOINT URL>>
</store>
</match>
|
其中<<ENDPOINT URL>>需要置換成您的Apps Script所發佈的存取URL,讓資料可以從這個點分流到Apps Script中的Endpoint。
Step 3: 設定排程器
然後,我們需要在Apps Script的排程器上面設定Query的執行時間間隔,讓Apps Script每固定時間確認一次,然後執行需要執行的排程。
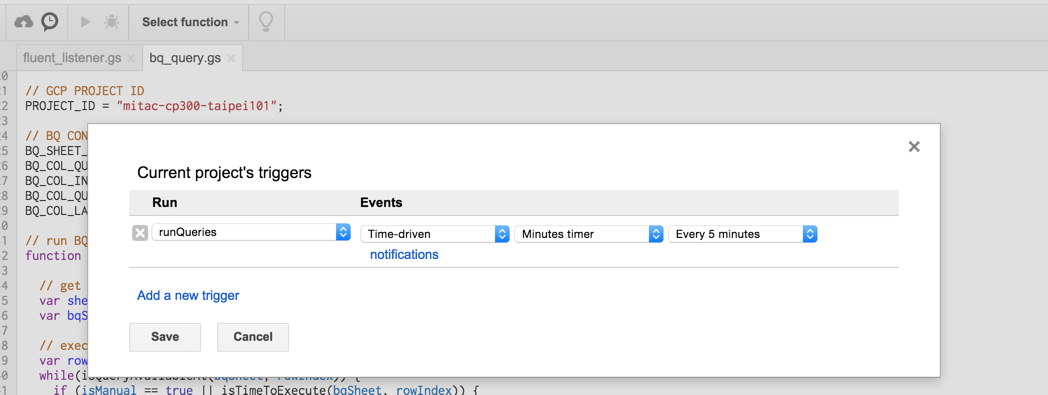
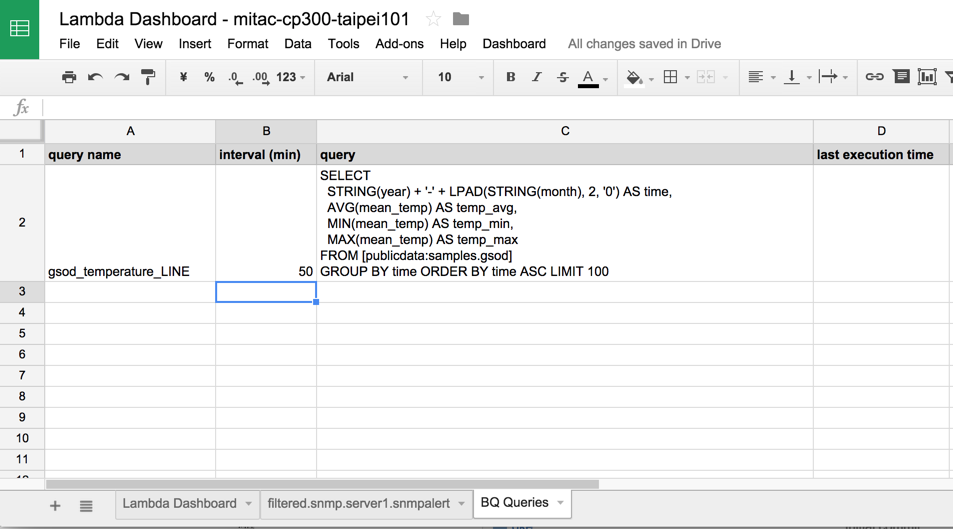
Step 4: 自定Query語法
最後我們只需要在Lambda Dashboard的Spreadsheet中的BQ Queries這個Tab加入我們所需要的查詢以及設定排程的interval時間,
進階的Lambda Architecture
最後,給大家一個Google上所有大資料相關工具的概觀,未來可以以Lambda Dashboard的方式來實作更穩定、更健全的Lambda Architecture:
上面的這些系統包含:
- 資料持續接收層:以Google Managed的服務方式存在,使用者只要會使用它,可以達到極小化管理的目的。
- Cloud Logging
- Cloud Storage
- Cloud Pub/Sub
- BigQuery Streaming Insert
- 大資料查詢層:以無限量儲存為目的,讓資料持續存放,並且可以提供查詢能力,並在有限的時間內回覆結果。
- BigQuery
- Dataflow
- 客製化查詢的Query Engine
- 展示層:以Google管理的方式,讓使用者可以透過設定的方法來產生圖表,並且最終可以結合自動化通知機制,做到及時反應。
- Cloud Monitor
- StackDriver
以上,是Google目前所提供的大資料工具介紹,您也可以在最小的開發、維運的狀態下開始進行大資料的蒐集了!接下來的工作,就是開始從這些資料面去挖掘更有意義的資料,透過BigQuery來關聯查詢您期望的結果,這一切已經讓Google簡化了!
附註
[1]. Table Decorator: 參考 https://cloud.google.com/bigquery/table-decorators ,BigQuery在查詢中提供Hot Area的資料查詢,該區域的資料依照給定的範圍不一。
[2]. Daily Table: BigQuery中支援再from條件中以萬用字元一次查詢多個表格,在應用上,我們會以日期來切割表格,在查詢時再串連在一起做查詢。
留言
張貼留言